Retrieval-Augmented Generation
Experiments from my comfy place under a rock

A brand new feature in LLMs is “understanding” text. Pretty much all of the knowledge work can be abstracted to a simple instruction: Answer my question using the relevant context. LLM hype claims this is solved. I’ll show you that it’s very much not.
So we want to augment the generation, by retrieving relevant context. That is the heart of the RAG. But what is the relevant context? How do we find it, how do we provide it, how do we use it? Obviously, we can’t just provide everything, right?
In this article, I explore these problems and methods (yes, no fine-tuning):
- Given a menu, what is the healthiest option to pick? (provide everything)
- Works ok with small contexts.
- Given a set of emails, what does my trip look like? (Embeddings)
- Worked well for this use case (lot of reasonably small and different bits).
- Given the Czech Labor Code, what are my duties? (Graph RAG)
- Failed completely in many different ways.

As I am moving forward in the discovery of this apparently revolutionary technology that will doom us all, I’ve finally hit the RAG wagon. And because writing is a great tool to sort one’s thoughts, here I am again. I hope that my fellow luddites trying to learn and ditch that status will find this post useful.
Once again we are searching for a trick to make the LLMs more useful. This time the problem is, that we have some specific information the LLM should use when answering. Imagine:
- You want to expand a document with some industry specific shorthands,
- You want to make a case referencing internal company policies (don’t put the policies into the LLM if there’s another policy that forbids it!)
- You want to automate something according to a large handbook, so you need relevant parts at relevant times.
So, let’s review some of the approaches to tackle this issue, starting with the most naive one.
Hope LLMs Know Everything They Need
To be fair to the big models, they do know quite a lot. You can get plenty of knowledge without any supplements in an absurd amount of topics ranging from art, through fitness, programming and up to zoology.
If you’re just exploring options and trying to enter a particular topic, then it makes sense to just go for it. In my opinion this is where the hype for the LLMs come from, obviously one single person isn’t able to replicate this at all.
The particular details of your setup won’t be taken into account if you don’t pass it to LLMs. Every expert in every field differentiates domain knowledge from the particular context of the problem.
Fortunately for humans, confidently stating subtly incorrect facts can and will hit a reality-check from time to time. So there is still some room for expertise. Unfortunately for humans, we have a growing toolset of options to extend these LLMs.
Just Put It All Into The Prompt™
This is the first obvious idea on how to accomplish this. I have a resource, I want to reference, so I can just fully give it to the LLM, like so:


The menu is from https://www.bramborynapankraci.cz/eng/menu/. It goes on for a while.
But what if your context is longer? Think a book - that’s 500 pages or approx 320k tokens. Even if your model context window allows it, you are usually paying for the token, so it might not be a good enough deal. And you can easily imagine more context - think legal cases, contracts, policies, textbooks. What do we do then?
Fine Tuning - Expensive and Complex
You could try and provide additional training to your LLMs with the data and insights you hope to capture. I have to admit that I didn’t try this at all and that’s for the following reasons:
- Training is expensive: you’d abuse a GPU cluster to get it done. Not only I don’t have such a cluster in my pocket, but I don’t want to pay the clouds for one either.
- Getting training data is hard: to have any shots at modifying the model, you need quite a lot of high-quality data. That’s hard, check this or check this for a quick intro.
In the end, the bitter lesson (seriously, go read this link) states that this approach should win in the end. That machines will outsmart us by brute force. Maybe, maybe.
As a bridge to the next topic, I’ve stumbled upon an article about RAFT (Retrieval Augmented Fine Tuning). Not to be confused with Raft, the consensus algorithm. The researchers are exploring methods in fine tuning the LLMs to teach them for “open book exams” claiming that selecting relative sources is a skill that needs to be trained for. I agree - this is something to watch for in the near future.
Embeddings - “Classic” (Naive, Top-k) RAG
You know that computers work with 0s and 1s. Perhaps you know that LLMs multiply a ridiculous amount of floating point numbers behind the scenes organized neatly into vectors and matrixes of a sufficiently high dimension.
Any text to process is then brought to a vector of these numbers. What’s important is that all of these vectors have the same dimension. So what that enables us to do, is to compare their distance (if you can imagine distance between two points on a 2D plane, then higher dimensions work in a similar manner1). And we hope (hope!!) that vectors that are close together are semantically related.
An embedding is then a representation of a piece of text (chunk) as a vector of floats. It is critical that one model embeds all of our data, else we will lose the semantic closeness property.
We can split our data into sufficiently small chunks, compute their embeddings and store them in a vector database (I’ve used faiss-cpu). Then for any query we compute the embedding of the question text and we’d bring together the data related (the top k related vectors, where k is a small enough number) to the vectors that are close to the query vector.
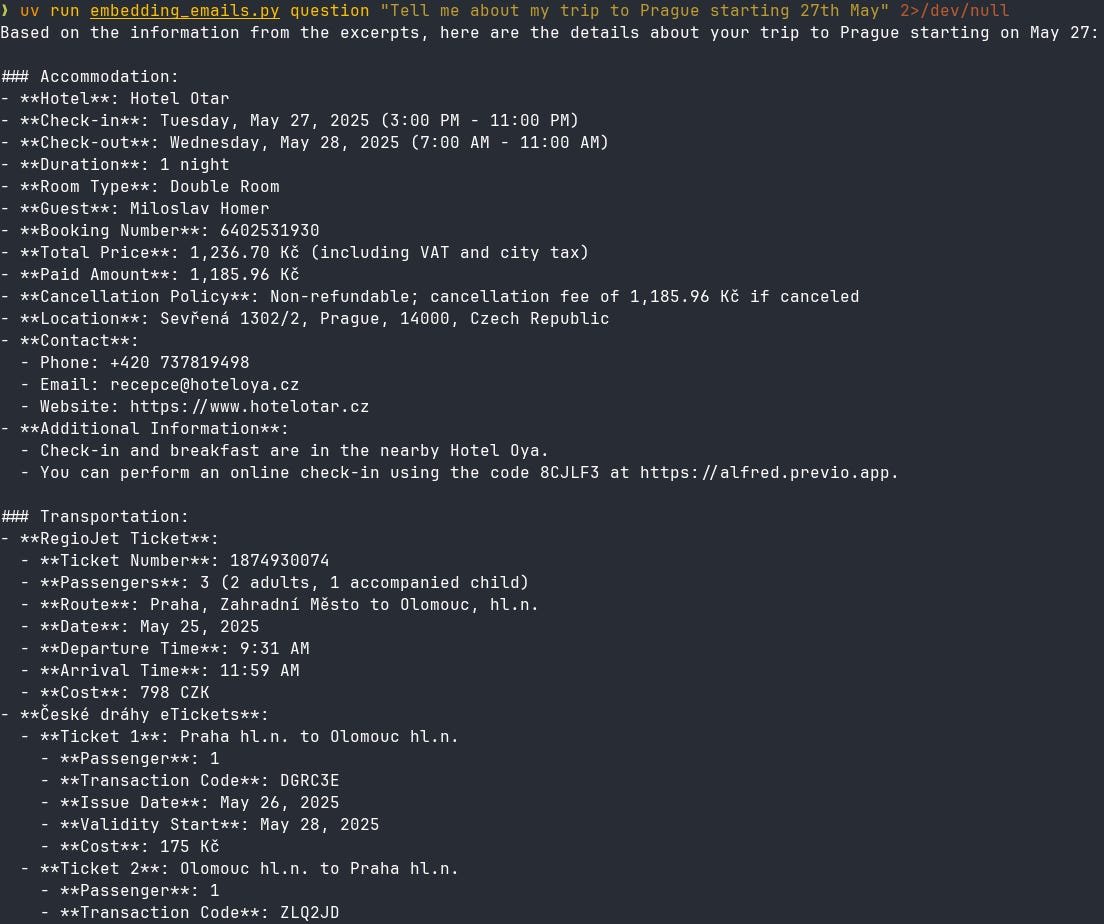
Now that was a lot of words, let’s setup an example. I have a Thunderbird email client. I want to ask some questions to my emails2 without painstakingly digging through the inbox. So the plan is simple - embed parts of email bodies in step one, then embed question in question for step 2. Find close vectors to add to the prompt and then prompt it.
I was surprised to see it working:

My guess would be that this approach works best when your data are “far from each other”. Emails about bookings are very different to emails about newest books to buy. And as a very related example, the bot wasn’t able to separate the trips on different dates (I was in Prague a couple days before with my family, but that’s already done, so I don’t really want to see it here).
There are, of course, plenty of opportunities for improvement. Giving the bot access to MCP tools for dates, maps and other things would improve the usefulness of this PoC dramatically. Hell, I might do it later, I grow tired of digging through the emails.
Graph RAG For Subtlety
So, how do we manage these subtleties then? A promising approach seems to be using knowledge graphs. I think I’ve reached the cutting edge, so I’d expect that we’ll be hearing about new techniques soon.
You can imagine a knowledge graph as a graph of knowledge. On a serious note, the nodes are entities and the edges are relationships of such entities. Imagine there’s a car entity a Porsche entity - these would have “is a brand of” relationship.
As an intuition, think of taking notes. You want to bring the pieces and note some relationships between them. Think bigger, you’d get the Wikipedia. Think bigger and you’ll get the internet with the Google search.
So, with this technique, we teach the LLM to use when tackling a problem. My loop goes as follows:
- LLM: This problem looks similar to what I know.
- Graph: What else do I know about the problem, how it’s related? When should I stop delving further?
- LLM: How do I distill all of this information to an answer?
Building a good set of notes will make or break this approach. And since I am either going big or going home, I’ve decided to tackle the Czech employment law. The issue with this approach is, that you need quite a big problem to let it shine. If your graph is small, who’s to say that “just put it all in prompt” won’t do the trick?
In the first phase, you need to construct the said graph. This is also not easy, since we’re looking at so much text (300 pages+). So once again, we enlist LLMs for help. I’ve found this prompt that gives me reasonable results for small chunks. But how do you chunk it? Per paragraph, per section, per part? Give too much context, LLM will drown in it. Give too little and the result is inconsistent. Maybe the bitter lesson is in order here.
Why do I keep getting into these complicated problems?
As I was tinkering with this, I’ve realized that there is some skill and method to prompt engineering. Provide examples, state important points multiple times, provide an overview and some details in steps (and couple others for sure). You really need a way to store and compare versions of a prompt to see if you’re moving in the right direction. Fortunately, these are text based and git is an excellent tool for that.
Then you need to verify the results consistently, ideally using a test suite. That’s however quite complicated if you don’t yet understand the text you’re trying to evaluate, because then you can’t setup tests that demonstrate this understanding. I’d call an expert, if we didn’t automate them away.
In the end, I’ve fallen flat on my face. A quick overview of my issues:
- I wasn’t able to get the LLM to create a consistent graph and the relationships are lost if you have 5 different entities for employees that differ in a letter or a suffix.
- I’ve also noticed that in some paragraphs, the LLM failed to include bits and pieces of context that I could ask for. I am no legal expert, but omitting the salary tier concept from a paragraph about salary tiers sounds like a big deal.
- Subtlety was lost: in the Czech language, there’s a huge difference between “není” (it is not) and “není-li” (unless). The LLM completely failed in this case and a couple of others, confusing these words.
Of course, you can tinker endlessly with this - try embeddings to bridge the gap to entities, try including more of the context here and there. But that’s work, and the promise was that LLMs will solve these pesky knowledge problems without work. If I paid for it, I would want my money back.
I get to keep my job for now (Yay!)
In a sense, that’s good for me. Now I know how exactly would an LLM fail at my work and why some naive approaches work and how their limits look like. I have an overview of the current methods and I am able to keep up with news again.
Working with these LLMs is a skill like any other and we knowledge workers would benefit from learning it. If pen and paper compares to hammers, programming compares to power tools, then LLM is a mech suit. Just hope you’re piloting it in a way that doesn’t squish your flesh within.
This is a hot topic of research, so I’d expect some novel methods to come and improve our current approaches and understanding. I hope I can appreciate/criticize them without blindly falling for the hype.
Actually, the concepts of distance do fall apart in the higher dimensions in a subtle ways. In our trusty 2D plane, for any given vector we have exactly two more that are orthogonal to it. In 3D plane, this goes further, we now have a full 2D plane of orthogonal vectors. This has plenty of weirdness as a consequence (as pointed by this comment). Check these links if you want to go further down this rabbit hole:
To find the Thunderbird emails, you need to check your home directory where it caches files. On linux it’s something like ~/.thunderbird/5va6p10e.default-default and there you’ll find plenty of sqlite files. I’ve found all data I needed in theglobal-messages-db.sqlitefile, I had to join two tables to do that, nothing fancy. Check the source code.